 |
|
Interface de Búsqueda iAH! versión 2 |
| BIREME home page: www.bireme.br | iAH home page: www.bireme.br/isis/P/iah.htm |
| e-mail: peml@bireme.br | |
Manual de Instalación
Sumario
| ¿ Qué es iAH? |
La interface de consultas iAH es una herramienta diseñada para dar pleno acceso a las capacidades de recuperación de información de las bases de datos CDS/ISIS. La recuperación en las bases de datos puede ser hecha a través de expresiones booleanas o accediendo a los índices del archivo invertido. La interface está escrita en IsisScript para ser ejecutada con el Servidor WWWISIS XML IsisScript - WXIS desarrollado por BIREME.
| ¿Dónde se instala iAH? |
La interface de consulta debe ser instalada bajo un servidor Web. El programa WXIS es el componente activo de la interface, funcionando como un servidor de acceso multiusuario a bases de datos CDS/ISIS. Existen versiones compiladas del programa para diversos sistemas operativos, entre ellos: Windows, Unix, Linux.
|
En todo servidor Web existe una estructura de directorios para su operación. A los efectos de los ejemplos de este manual se asumirá que la estructura de directorios es la que se enseña en la figura a la derecha. En general existen equivalencias entre los directorios de los servidores Web y la estructura propuesta en la figura 1. La tabla siguiente muestra otras estructuras similares para servidores Web en el mercado. Es posible hacer adaptaciones y variantes a este esquema para acomodar los directorios de acuerdo a implementaciones específicas. |
|
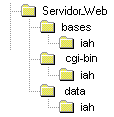
| Propuesto | OmniHTTPd | MS IIS | Apache |
| Servidor_Web | httpd | Inetpub | httpd |
| Cgi-bin | cgi-bin | scripts | cgi-bin |
| Data | HtDocs | wwwroot | html |
| ¿Quién Instala iAH? |
Para instalar la interface es necesario tener los conocimientos básicos para realizar las operaciones de mantenimiento de sistemas computarizados, tales como la creación y eliminación de directorios, copia, edición y eliminación de archivos, asignación de derechos de acceso, etc., además tener conocimientos del servidor Web a ser utilizado.
| Paquete de Instalación |
|
El paquete de la interface se distribuye en un directorio llamado iAH con todos los archivos y subdirectorios necesarios para la interface. A creación del directorio, depende de la plataforma operativa. Para sistemas Windows 9x/NT es enviado un ejecutable (iAH.exe), que después de ejecutado crea un directorio conforme ilustrado en la Figura-2 (para ejecutar: Botón Iniciar ® Ejecutar ® "a:\iah.exe"). Para sistemas UNIX y similares es enviado un archivo TAR (iAH.tar), que después de abierto crea un directorio conforme ilustrado en la Figura-2 (para abrir el archivo ejecute el comando: tar -xf iAH.tar *). El paquete está compuesto por tres conjuntos de archivos: el conjunto bases, el conjunto cgi-bin y el conjunto data. Cada uno de esos contiene un subdirectorio también llamado iAH. Bajo cada uno de estos subdirectorios existen a su vez otros subdirectorios, tal como se describen a continuación. |
|
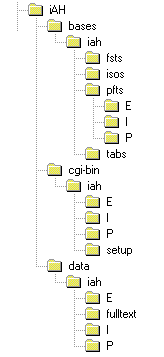
| ruta IAH/BASES/IAH |
Hay cuatro directorios: fsts; isos; tabs; y pfts, y tres archivos: setupbd.bat; setupbd.xis; wxis.exe. En los directorios están los archivos necesarios para ejemplificar la instalación de bases de datos en la interface, hay disponibles dos bases de datos con una pequeña cantidad de registros, una Secs y una Lilacs. En el directorio fsts se encuentran las tablas de seleción de campos para aplicarse a las bases. En el directorio isos están los archivos exportados de las bases de datos (los que serán importados durante el proceso de setup). En el directorio tabs hay varios archivos de bases de datos en formato ISO que operan de forma complementaria con la interface, sea sirviendo de tablas de conversión de caracteres u otras tareas de naturaleza semejante. En el directorio pfts están los diversos formatos de presentación para las bases de dados. Los archivos son destinados a mantenimiento de las bases de datos.
| ruta IAH/DATA/IAH |
Contiene quatro directorios (E; I; P; y fulltext) y cinco archivos (iah.def; dblil.def; dbsecs.def; bases.htm; y setup.htm). En el directorio iah/data/iah/fulltext se encuentran algunos archivos para ejemplificar textos completos. En cada uno de los directorios E; I; y P hay los subdirectorios image y help. En los directorios image se encuentran los archivos de imágenes usados por la interface, teales como íconos, botones, banners, logos e etc. En los directorios help están los archivos con los textos de ayuda de la interface en formato HTML. Los archivos con extensión DEF, contienen una serie de definiciones de la interface (IAH.DEF) y cada base de datos (DBSECS.DEF para la base SECS, y DBLIL.DEF para la base LILACS), el archivo setup.htm se utilizará en la operación de configuración de la interface y finalmente el archivo bases.htm da acceso a la interface de consulta para cada una de las bases de datos.
| ruta IAH/CGI-BIN |
Aquí se encuentra el programa WXIS.EXE que interpreta y ejecuta el contenido de los scripts.
| ruta IAH/CGI-BIN/IAH |
Hay cuatro directorios (setup; E; I; P) y dos archivos de IsisScript. Los scripts son: setup.xis y iah.xic, respectivamente usados para configurar la interface y ejecutala. En el directorio iah/cgi-bin/iah/setup hay un conjunto de archivos HTML que componen las páginas del proceso de setup de la interface, estos archivos son utilizados según lo requiere el control del script SETUP.XIS. En los directorios E; I; P están los archivos de formato, usados para montar las diversas partes de las páginas que componen la interface, en sus idiomas correspondientes.
| ¿Como Instalar iAH? |
Los directorios y archivos mencionados deben ser copiados en los lugares adecuados al servidor Web, como veremos en los detalles a continuación; primero de todo es necesario conocer algunos datos sobre el servidor Web que recibirá la interface. Debe recopilarse las siguientes informaciones:
- Sistema operativo (ej.: Unix, Windows 95, etc.);
- Raíz del servidor Web (ej.: /httpd/HtDocs);
- Directorio de ejecución de CGI / Scripts (ej.: /httpd/cgi-bin);
- Ubicación de las Bases de Datos (ej.: /httpd/bases).
Para implantar la interface, aquí llamada de aplicación, que pueda ser utilizada con una o más bases de datos, serán creados directorios respectivos para cada uno de los componentes.
La descripción que sigue muestra un proceso de instalación estándar para la interface, o sea usando iAH como nombre de la aplicación, basado en el servidor Web OMNIHTTPd en su configuración patrón de directorios (ver Tabela-1).
| Directorios para las Bases de Datos |
|
Como se explicó anteriormente (ver Figura-1), en la estructura de directorios del servidor Web, hay una ubicación específica para almacenar las bases de datos. Es posible crear tantos subdirectorios como se desee si eso facilita el mantenimiento de las bases de dados. En la Figura-3, a la derecha, se muestra el esquema de directorios para la instalación del paquete de distribuición. |
|
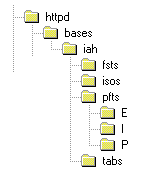
| Procedimientos para la instalación del paquete: |
1. Transferir para el directorio donde estarán las bases en el servidor Web, los archivos presentes en /iAH/bases del paquete de instalación, así como sus subdirectorios (ver Figura-2).
| Directorios para las Páginas de Acceso a la Interface |
|
En el servidor Web debe haber un directorio para almacenar las páginas estáticas de acceso a la interface de consultas, los archivos de configuración del sistema y de configuración de las bases, además de subdirectorios para: imágenes, textos completos y ayuda en cada uno de los idiomas de la interface. Este directorio debe estar debajo de la raíz del servidor Web y tendrá el mismo nombre de la aplicación. La Figura-4 a la derecha muestra la ubicación del directorio de la aplicación (iah), debajo del directorio raíz del servidor Web (httpd/HtDocs), en este directorio deben estar los archivos con extensión DEF utilizados para almacenar las configuraciones, tanto de la aplicación como de las bases de datos a ser operadas. En fulltext, debajo de iah, estarán los archivos de textos completo que sean usados. En cada uno de los directorios del idioma (E; I; y P) hay los directorios image y help. En image, estarán todos los archivos de extensión GIF e JPG utilizados en la interface. En help, estarán los archivos de ayuda de operación de la interface. |
|
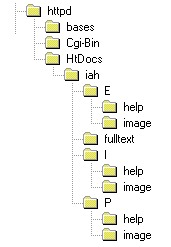
| Procedimientos para la instalación del paquete: |
1. Transferir para el directorio raíz del servidor Web (directorio de páginas html), los directorios presentes en /iAH/data del paquete de instalación, así como sus subdirectorios (ver Figura-2).
| Directorio para la Ejecución de Scripts |
|
En el servidor Web debe haber un directorio de ejecución de CGI, en este directorio debe ser colocado el programa WXIS.EXE y debajo de este directorio estará un directorio para la aplicación (en nuestro ejemplo iAH) que contendrá los archivos de IsisScript correspondientes a la aplicación, y cuatro subdirectorios, setup, E; I; y P. En el directorio setup estarán las páginas HTML del processo de configuración de la aplicación. En los directorios de idioma (E; I; y P) estarán los archivos de formato que montan las pantallas del sistema en forma dinámica. |
|
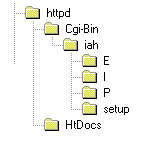
| Procedimientos para la instalación del paquete: |
1. Transferir para el directorio de ejecución de cgi / scripts del servidor Web los archivos existentes en /iAH/cgi-bin del paquete de instalación, así como sus subdirectorios.
Luego de haber copiado todos los componentes en los debidos lugares del servidor Web, deberán realizarse algunos ajustes en el archivo de definición global de la interface IAH.DEF, ubicado en el directorio iah de la raíz del servidor Web, los ajustes se refieren a las rutas de localización de las bases de datos , a las páginas de acceso a la interface, y al directorio de ejecución de los scripts.
| Edición del archivo IAH.DEF |
El archivo IAH.DEF, es un archivo texto compuesto de cuatro (04) secciones, cada una de ellas con funciones específicas. Las secciones y sus funciones se muestran en la Tabla-2 que sigue:
| [PATH] | v | Indica ubicaciones de los archivos |
| [APPEARANCE] | v | Determina algunos ítems de la apariencia de la interface |
| [HEADER] | v | Define imágenes y links para los encabezamientos de las páginas |
| [IAH] | v | Indica el responsable y estados posibles de la interface |
Las declaraciones contidas en la sección [PATH] son las que se describen a continuación:
- PATH_DATA:
- Indica la ruta relativa a la raíz del servidor Web, donde estarán las páginas estáticas (IAH en el ejemplo de la Figura-4);
- PATH_CGI-BIN:
- Indica la ruta absoluta al directorio de ejecución de CGIs y scripts (/httpd/cgi-bin/iah en el ejemplo de la Figura-5);
- PATH_DATABASE:
- Indica la ruta absoluta al directorio donde se encuentran las bases de datos (/httpd/bases/iah en el ejemplo de la Figura-4).
Las declaraciones contidas en la sección [APPEARANCE] son las que se describen a continuación:
- BODY BACKGROUND COLOR:
- determina el color de fondo de las páginas HTML del sistema;
- BODY BACKGROUND IMAGE:
- determina la imagen de fondo de las páginas HTML del sistema;
- BODY TEXT COLOR:
- determina el color del texto de las páginas HTML del sistema;
- BODY LINK COLOR:
- determina el color de los links de las páginas HTML del sistema;
- BODY VLINK COLOR:
- determina el color de los links visitados de las páginas HTML del sistema;
- BAR BACKGOURND COLOR:
- determina el color de las barras del sistema;
- BAR TEXT COLOR:
- determina el color de los textos en las barras del sistema.
Las declaraciones contidas en la sección [HEADER] son las que se describen a continuación:
- LOGO IMAGE:
- determina la imagen de logotipo que es usada para componer el encabezamiento de las páginas HTML del sistema. Esa imagen debe estar en el directorio images, tal como se ilustra en la Figura-3;
- LOGO URL:
- determina la URL del site que hospeda la interface iAH;
- HEADER IMAGE:
- determina la imagen de encabezamiento de las páginas HTML del sistema. Esa imagen debe estar en el directorio images, tal como se ilustra en la Figura-3;
- HEADER URL:
- determina la URL de la página inicial de la interface iAH (página de selección de bases);
Las declaraciones contidas en la sección [IAH] son las que se describen a continuación:
- MANAGER E-MAIL:
- determina el e-mail del administrador del sistema. Ese e-mail es informado al usuario en algunos casos de error en el sistema;
- REVERSE MODE:
- determina como debe se desplegado el resultado de la búsqueda, si en ordem ascendente (OFF), o inverso (ON) de MFNs;
- MULTI-LANGUAGE:
- Indica si el usuario puede cambiar el idioma de la interface. Cuando el valor es OFF el cambio no puede ser hecho, cuando el valor es ON el usuario puede cambiar, entre los idiomas inglés, español y portugués.
| Procedimientos para la instalación del paquete: |
1. Abrir el archivo IAH.DEF con un editor de textos;
2. Localizar la sección [PATH];
3. En la línea con la declaración PATH_DATA, digitar a continuación del signo de igual (=), la ruta relativa al directorio que contiene las páginas estáticas, en nuestro ejemplo será /iah/. Es importante que se digiten las barras al inicio y al final de las rutas;
4. En la línea con la declaración PATH_CGI-BIN, digitar a continuación del signo de igual (=), la ruta absoluta del directorio que contiene los scripts, en nuestro ejemplo /httpd/cgi-bin/iah/. Nuevamente es importante que se digiten las barras al inicio y al final;
5. En la línea con la declaración PATH_DATABASE, digitar a continuación del signo de igual (=), la ruta absoluta del directorio que contiene las bases de datos, en nuestro ejemplo /httpd/bases/iah/. Nuevamente es importante que se digiten las barras al inicio y al final;
6. Salvar el archivo.
| Prueba Inicial del Sistema |
Después de ajustar el
archivo IAH.DEF, debe abrir la página inicial del sistema
con un navegador de web, utilizando la dirección:
http://servidor/iah/iah.htm, donde
servidor será el nombre de su servidor Internet donde
está instalando el paquete. Si la instalación se está
haciendo localmente en el servidor, es posible usar
localhost como nombre
del servidor. A partir de esta página se puede acceder a la p�gina de selecci�n
de las bases de ejemplo que vienen en el paquete o ir al m�dulo de administraci�n.
La primera vez que se realiza la instalación es conveniente ejecutar
la b�squeda en las bases de datos de ejemplo (LILACS
y SeCS), y luego de
verificar que la interface funciona pasar a instalar las bases de datos propias.
| Bases de Datos Propias |
Para instalar una base de datos propia, es necesario cumplir con los siguientes pasos:
1. Transferir para el directorio ISOS (bases/iah/isos) lo(s) archivo(s) ISO de la(s) base(s) de datos (ver Figura-3);
2. Transferir para el directorio FSTS (bases/iah/fsts) lo(s) archivo(s) FST de la(s) base(s) de datos.
3. Transferir para el directorio PFTS (bases/iah/pfts) los archivos de formato de la(s) base(s) de datos. Nota: Los comandos de sangría y espaciamiento vertical e horizontal característicos del lenguaje de formato CDS/ISIS, en caso de existir, deben ser modificados por sus equivalentes HTML. Asimismo, si algún campo de la base de datos usa marcas para la alfabetización (filing information), por ejemplo <A>, <The>, <La>, etc, deberá modificar el modo de exibición de ese campo a modo de encabezamiento (mhl);
4. Ejecutar el setup de la base de datos:
4.1. En ambiente windows abra una ventana DOS;
4.2. Cambie para el directorio de las Bases de Datos (ej.: /httpd/bases/iah);
4.3. Ejecute el módulo de setup informando el nombre del archivo ISO (incluyendo extensión), nombre del archivo da tabla de selección de campos (incluyendo extensión) y el nombre de la base de datos resultante.
(ej.: setupdb.bat base.iso base.fst base) 5. Crear una copia del archivo DBLIL.DEF llamada <su_base>.DEF y editar las líneas que sean necesarias para adecuarlo a su base de datos, de acurdo a las instrucciones que se dan en la sección Configuración de Bases de Datos;
6. Agregar a la página de acceso a las bases de datos una referencia a la nueva base de datos, de acuerdo al modelo siguiente:
<A HREF = "/cgi-bin/wxis.exe/iah/?IsisScript=iah/iah.xic&base=base&lang=e">base</A> - Texto descriptivo de la base de datos
los términos en negrita son los que deben ser alterados para adaptarse a la base de datos propia.
| Configuración de Bases de Datos |
La configuración de una base de datos se hace mediante un archivo de definición de base de datos, llamado según la base [base].DEF, donde [base] es el nombre de la base de datos a ser configurada.
El archivo base.DEF es un archivo texto compuesto de seis (06) secciones, cada una con funciones específicas. Las secciones y sus funciones se muestran en la Tabla-5 siguiente:
| [FILE_LOCATION] | v | Definición de archivos para acceso a las bases de datos |
| [INDEX_DEFINITION] | v | Definición de los índices accesibles para las consultas |
| [APPLY_GIZMO] | v | Definición de los archivos para los cambios globales de contenidos |
| [FORMAT_NAME] | v | Definición de los formatos disponibles para la presentación |
| [HELP_FORM] | v | Definición de los archivos de ayuda para los formularios de consulta y índices |
| [DISPLAY_FORM] | v | Relación de formularios de consulta disponibles |
En la sección [FILE_LOCATION] se definen los nombres lógicos de acceso y también se asocian estos nombres con los nombres físicos de los archivos.
Como mínimo se definen tres (03) archivos: una base de datos; el o los archivos invertidos; y los archivos de formato de presentación. El nombre lógico DATABASE es obligatorio pues es quien define el archivo de la base de datos.
Todas las definiciones comienzan por el término reservado FILE, de modo que una definición tiene la siguiente sintaxis general:
FILE NOMLOGIC.*=/directorio-1/directorio-n/nomarchivo.*
Usando la definición de la base de datos LILACS como ejemplo la declaración sería:
FILE DATABASE.*=/httpd/bases/iah/dblil.*
Sin embargo, para facilitar esta declaración es posible usar las referencias por variables. Hay tres variables definidas por el sistema: %path_database%; %path_cgi-bin% y %lang%. Donde %path_database% y %path_cgi-bin% reciben como valor las declaraciones efectuadas en la sección [PATH] de IAH.DEF, PATH_DATABASE y PATH_CGI-BIN respectivamente. Además, %lang% recibe la identificación del idioma de la interface de acuerdo al patrón: I para inglés; E para español; y P para portugués, permitiendo variaciones en función del idioma de la interface, por ejemplo formatos distintos para la base de datos según el idioma.
De esta manera, la definición de los archivos podría ser como sigue:
FILE DATABASE.*=%path_database%dblil.*
Una definición de formato, podría ser como sigue:
FILE standard.pft=%path_database%pfts/%lang%/lildhtm.pft
Siempre basado en la estructura propuesta para ejemplificar la instalación del paquete.
En la sección [INDEX_DEFINITION] se definen todos los índices accesibles en la búsqueda. Es posible montar una FST para cada índice o una FST con prefijos.
Todas las definiciones comienzan por el término reservado INDEX, y están compuestas por hasta nueve (09) elementos (subcampos), de acuerdo al detalle de la Tabla-6 siguiente:
| ^p | Nombre del índice en el idioma portugués |
| ^e | Nombre del índice en el idioma español |
| ^i | Nombre del índice en el idioma inglés |
| ^d | Especifica si el índice es el índice por defecto |
| ^s | Lista de identificadores de campo onde se desea realizar la b�squeda |
| ^t | Tipo del índice ("short" para índice corto) |
La forma general de una definición de índice es la siguiente:
INDEX XX=^pNome^eNombre^iName^d*^s99
Un índice de palabras quedaría como en el ejemplo siguiente:
INDEX TW=^pPalavras^ePalabras^iWords^d*
En este ejemplo el índice se mostrará en la interface como Palabras (en el idioma de la interface español), será usado como índice por defecto, y ir�r realizar la b�squeda en todos los campos definidos en la FST.
Para definir el índice de autores podrá usarse una declaración como la que sigue:
INDEX AU=^pAutor^eAutor^iAuthor^s10,16,23^fA
En la sección [APPLY_GIZMO] se indican las bases de datos que se usarán para realizar los cambios globales de caracteres contenidos en los campos de una base de datos CDS/ISIS, de modo de poder convertir una cadena de caracteres en otra, como ser, modificaciones, codificación/decodificación, compresión de datos, etc.
Todas las definiciones comienzan por el término reservada GIZMO, con la siguiente forma general:
GIZMO NOMLOGIC
El paquete de instalación viene con cuatro (04) bases gizmo predefinidas:
| ASC2ANS | - | Efectua la conversión de caracteres del conjunto ASCII en caracteres ANSI. |
| QLFE | - | Efectua la decodificación de calificadores de términos DeCS para español |
| QLFI | - | Efectua la decodificación de calificadores de términos DeCS para inglés |
| QLFP | - | Efetua la decodificación de calificadores de términos DeCS para portugués |
De esta manera se puede determinar la aplicación de la base GIZMO ASC2ANS cuando se desea exhibir por la interface una base que utiliza el conjunto de caracteres ASCII, usando la declaración:
GIZMO=ASC2ANS
En la sección [FORMAT_NAME] se definen los nombres lógicos de los formatos disponibles para la presentación de los resultados de las consultas y las descripciones en los tres idiomas.
Todas las definiciones comienzan con el término reservado FORMAT y a continuación se dan las declaraciones de las descripciones para cada idioma con los correspondientes identificadores de subcampo: ^p para portugués; ^e para español; y ^i para inglés). De esta manera una definición tiene la siguiente sintaxis:
FORMAT xxxxx=^pnononon^eonononono^imomomomo
El paquete de instalación tiene cuatro (04) formatos disponibles: largo; detallado; citación; y titulo. El formato largo se asume como formato por defecto. Los archivos PFT definidos para cada uno de los nombres lógicos aquí indicados deben ser declarados en la Sección [FILE_LOCATION].
La definición del formato detallado podría declararse de la manera siguiente:
FORMAT detailed.pft=^pDetalhado^eDetallado^iDetailed
La declaración especial FORMAT DEFAULT define cuál es el formato por defecto para la presentación de resultados al activarse la interface. Esta declaración debe ser la última de la sección y debe referir a alguna de las declaraciones efectuadas más arriba en la sección, como se muestra en el ejemplo siguiente:
FORMAT DEFAULT=detailed.pft
En la sección [HELP_FORM] se definen los archivos HTML de ayuda y notas explicativas para cada uno de los tipos de formulario (libre, básico y avanzado) y/o índices disponibles en la consulta y que deben estar localizados en el directorio help debajo de cada directorio de idioma (P, E, I), tal como se ilustra en la Figura-4.
Los textos de ayuda y notas explicativas, pueden ser genéricos, sirviendo a todos los elementos de una categoría (formulario o índice), o específicos para determinado elemento de una categoría. Por ejemplo, se puede definir un archivo de ayuda para todos los índices disponibles y adicionalmente un archivo de ayuda que detalle mejor un de los índices del conjunto.
Todas las definiciones de texto de ayuda genérico comienzan con los términos reservados HELP FORM o HELP INDEX y a continuación la definición del nombre del archivo, en este caso físico. De esta manera una definición tiene la siguiente sintaxis:
HELP FORM=ayuda_forms.html
HELP INDEX=ayuda_indices.html
Para las definiciones de texto de ayuda específicos debese añadir una definición del tipo de formulario (F-formulario libre; B-formulario básico; o A-formulario avanzado) y/o índice (de acuerdo a las definiciones en la sección INDEX_DEFINITION), ejemplos:
HELP FORM F=ayuda_form_libre.html
HELP INDEX TW=ayuda_indice_palabras.html
Para las definiciones de notas explicativas, debese usar los términos reservados NOTE FORM y NOTE INDEX en lugar de HELP FORM y HELP INDEX, los demás procedimientos quedan iguales.
En la sección [PREFERENCES]
se definen algunos estados posibles de la interface para la base de datos. Las declaraciones contidas
en esa secci�n son las que se describen a continuaci�n:
| F | Formulario de Consulta Libre |
| B | Formulario de Consulta Básica |
| A | Formulario de Consulta Avanzada |
La definición comienza por el término AVAILABLE FORMS y a continuación por la lista de identificadores de formularios disponibles, separados por comas. El primero de la lista será el formulario por defecto al activarse la interface, como en el ejemplo que sigue:
AVAILABLE FORMS=F,A
donde se definen los formularios disponibles: Consulta Libre y Consulta Avanzada, siendo el formulario Consulta Libre que se activa por defecto al abrir la interface.
- SEND RESULT BY EMAIL
- Valores posibles (ON o OFF), habilita o no el
envio de resultado por e-mail a trav�s de un programa (mailer) externo por SMTP.
La l�nea de comando que ser� ejecutada cuando esta opci�n esta activa debe ser configurada en el archivo sendmail.conf ubicado en el directorio iah en el raiz del servidor Web (p.ex.: /httpd/data/iah/).
NOTA: el programa responsable por el envio del e-mail no es parte del paquete del sistema.
- NAVIGATION BAR
- Valores posibles (ON o OFF), muestra o no la barra de navegaci�n entre los documentos recuperados en una b�squeda.
- DOCUMENTS PER PAGE
- Informa el numero m�ximo de documentos en una p�gina del resultado.
| Apéndice A - Técnicas de Indización |
Una FST (Field Select Table) consiste en una o más líneas, cada una de las cuales define tres parámetros:
1 - un identificador de campo;
2 - una técnica de indización;
3 - un formato de extracción de datos en el lenguaje de formateo de CDS/ISIS.
Las técnicas de indización definen los procesos a ser realizados sobre los datos generados por el formato, con objeto de identificar los elementos específicos que serán creados. Hay nueve (9) técnicas de indización que se pueden utilizar. Estas reciben un código numérico del 0 al 8, tal como se explica a continuación:
| a. Técnica de indización 0 (cero) |
Genera un elemento a partir de cada línea extraída por el formato. Esta técnica es normalmente utilizada para indizar campos o subcampos completos. Nótese sin embargo, que CDS/ISIS construirá elementos a partir de líneas, no de campos. Esto se debe a que CDS/ISIS considera la salida del formato como una cadena de caracteres, donde los campos no son identificables sino las líneas resultantes. Es responsabilidad del usuario producir los datos correctos mediante el formato, especialmente si está indizando campos repetibles o concatenando más de un campo. En otras palabras, cuando se usa esta técnica, el formato de extracción debe producir como salida una línea por cada elemento a ser indizado.
| b. Técnica de indización 1 (uno) |
Genera un elemento a partir de cada subcampo o de cada línea extraída por el formato. Como CDS/ISIS buscará códigos delimitadores de subcampos en la salida del formato, para que esta técnica trabaje correctamente el formato debe especificar el modo proof (o sin modo alguno, ya que este es el modo implícito), debido a que éste es el único modo que conserva los códigos delimitadores de subcampos en la salida. Recuerde que los modos de encabezamiento y de datos sustituyen los códigos delimitadores de subcampos por signos de puntuación. La técnica 1 de selección de términos es una extensión de la técnica 0.
| c. Técnica de indización 2 (dos) |
Genera un elemento a partir de cada término o frase encerrada entre paréntesis triangulares < ... >. Cualquier texto fuera de estas marcas no se incluye en el índice. Nótese que para usar esta técnica se necesita usar el modo proof, ya que los otros modos eliminan los paréntesis triangulares.
Por ejemplo:
Relatório descrevendo um <curso universitário> em <treinamento de documentação> em uma <escola de biblioteconomia> africana
Producirá los elementos siguientes indizados mediante esta técnica:
curso universitário;Realiza el mismo proceso que la técnica 2 excepto que los términos o frases están encerradas entre barras inclinadas ( /.../ ).
treinamento de documentação;
escola de biblioteconomia.
Por ejemplo:
Relatório descrevendo um /curso universitário/ em /treinamento de documentação/ em uma /escola de biblioteconomia/ africana
Producirá los elementos siguientes indizados mediante esta técnica:
curso universitário;
treinamento de documentação;
escola de biblioteconomia.
| e. Técnica de indización 4 (cuatro) |
Genera un elemento a partir de cada palabra en el texto extraído por el formato. Una palabra es cualquier secuencia de caracteres alfabéticos contiguos. Nótese que cuando esta técnica se usa para indizar un campo completo que contiene delimitadores de subcampo, debe especificarse el modo de encabezado o el de datos (mhl o mdl) en el formato de extracción de datos correspondiente, de manera que se realice la sustitución de los delimitadores de subcampo antes de la indización, de otra forma los códigos delimitadores de subcampo serán considerados como parte de la palabra. También es aconsejable usar el modo de encabezamiento de datos si el campo indizado contuviera información para archivo (filing elements).
- Observación::
- La definición de los caracteres alfabéticos puede ser adaptada a las necesidades de cada usuario mediante la Tabla del Sistema ISISAC.TAB.
| f. Técnicas de indización 5, 6, 7, y 8 |
Las técnicas de indización 5, 6, 7, y 8 operan de forma idéntica a las técnicas 1, 2, 3, y 4, respectivamente, pero permiten especificar un prefijo para los términos extraídos.
El prefijo se especifica en el formato de extracción de datos como un literal incondicional de la siguiente manera:
'dprefixod',[formato CDS/ISIS]
donde:
| d | es el delimitador elegido que no será usado como parte del prefijo; |
| prefixo | cadena de caracteres que será usado como prefijo; |
| [formato CDS/ISIS] | formato de extracción de datos en lenguaje de formateo CDS/ISIS. |
Por ejemplo, para indizar cada palabra del campo 24 con el prefijo TI_ se debe montar la FST con la declaración siguiente:
24 8 '#TI_#',v24
que se descompone en los siguientes elementos:
| '#TI_#' | literal incondicional | |
| # | delimitador de prefijo | |
| TI_ | prefijo usado | |
| V24 | formato de extracción de CDS/ISIS |
A los efectos de comparación podemos observar, en la tabla siguiente, una FST con y sin uso de prefijos:
| Sin Prefijo | Con Prefijo |
| 70 0 MHU,(V70/) | Con Prefijo |
| 70 0 MHU,(V70/) | 70 0 MHU,('AU_',V70/) |
| 24 4 MHU, V24 | 24 8 MHU,'/TI_/',V24 |
| 69 2 V69 | 69 6 '/KW_/',V69 |
Es importante notar que la técnica de indización 0 (cero) admite el uso o no de prefijos, en cambio las otras técnicas deben ser especificadas, como se muestra en la tabla siguiente:
| Sin Prefijo | Con Prefijo | Operación de la técnica | ||
| 0 | ^ | 0 | ^ | Campo completo |
| 1 | ^ | 5 | ^ | Subcampo |
| 2 | ^ | 6 | ^ | Términos marcados com < ... > |
| 3 | ^ | 7 | ^ | Términos marcados con / ... / |
| 4 | ^ | 8 | ^ | Palabra por palabra |
| Apéndice B - Campos LILACS (Metodología BIREME) |
| Código de Centro | [01] |
| Numero de Identificación | [02] |
| Numero de llamada | [03] |
| Base de Datos | [04] |
| Tipo de Literatura | [05] |
| Nivel de Tratamiento | [06] |
| Numero de Registro | [07] |
| Medio Electrónico | [08] |
| Autor | [10] |
| Autor Institucional | [11] |
| Titulo | [12] |
| Titulo en inglés | [13] |
| Páginas | [14] |
| Autor | [16] |
| Autor Institucional | [17] |
| Titulo | [18] |
| Titulo en inglés | [19] |
| Numero Total de Páginas | [20] |
| Volumen | [21] |
| Autor | [23] |
| Autor Institucional | [24] |
| Titulo | [25] |
| Numero Total de Volumenes | [27] |
| Titulo | [30] |
| Volumen | [31] |
| Fascículo | [32] |
| ISSN | [35] |
| Información Descriptiva | [38] |
| Idioma del Texto | [40] |
| Idioma del Resumen | [41] |
| Diseminación de la Información | [42] |
| Instituición (tesis) | [50] |
| Título (tesis) | [51] |
| Instituición (conferencia) | [52] |
| Nombre (conferencia) | [53] |
| Fecha (conferencia) | [54] |
| Fecha Normalizada (conferencia) | [55] |
| Ciudad | [56] |
| País | [57] |
| Instituición (proyecto) | [58] |
| Nombre Proyecto | [59] |
| Numero Proyecto | [60] |
| Notas | [61] |
| Editora | [62] |
| Edición | [63] |
| Fecha de Publicación | [64] |
| Fecha Normalizada | [65] |
| Ciudad Publicación | [66] |
| País Publicación | [67] |
| Símbolo | [68] |
| ISBN | [69] |
| Tipo Publicación | [71] |
| Referencias | [72] |
| Alcance Tempo (desde) | [74] |
| Alcance Tempo (hasta) | [75] |
| Precodificado | [76] |
| Individuo como Tema | [78] |
| Geográfico no DeCS | [82] |
| Resumen | [83] |
| Descriptor Primario | [87] |
| Descriptor Secundario | [88] |
| Disponibilidad | [90] |
| Fecha de Proces. | [91] |
| Documentalista | [92] |
| Registro Complementar | [98] |
| Registro complementar | [101] (evento) |
| Registro Complementar | [102] (proyecto) |
| Registro Complementar | [103] (tesis) |
| Apéndice C - Campos SeCS Catalogo (Metodología BIREME) |
| Data Base Name | [1] |
| Tipo de Registro | [5] |
| Ident. del Contr. del Reg. | [6] |
| Codigo del Centro | [10] |
| Codigo Nacional | [20] |
| Numero de Registro | [30] |
| Numero SeCS | [37] |
| Sistemas Relacionados | [40] |
| Estado de la Publicación | [50] |
| Colección Compactada | [98] |
| Titulo de la Publicación | [100] |
| Subtitulo | [110] |
| Sección / Parte | [120] |
| Titulo Sección / Parte | [130] |
| Mención de Responsabilidad | [140] |
| Titulo Abreviado | [150] |
| Variantes Titulo - Paralelo | [230] |
| Variante Titulo - Otras | [240] |
| Fecha Inicial | [301] |
| Volumen Inicio | [302] |
| Fasciculo Inicio | [303] |
| Fecha Termino | [304] |
| Volumen Termino | [305] |
| Fasciculo Termino | [306] |
| País de Publicación | [310] |
| Estado/Provincia | [320] |
| Nivel de Publicación | [330] |
| Alfabeto del Titulo | [340] |
| Idiomas del Texto | [350] |
| Idiomas del Resumen | [360] |
| Frecuencia Actual | [380] |
| ISSN Vigente | [400] |
| "Coden" | [410] |
| Journal Code (Medline) | [420] |
| Clasificación | [430] |
| Descriptores | [440] |
| Cobertura de la Indización | [450] |
| Editor Comercial | [480] |
| Ciudad de Publicación | [490] |
| Fecha | [500] |
| Titulo (tiene edición otro idioma) | [510] |
| Titulo (es edición outro idioma) | [520] |
| Titulo (tiene subserie) | [530] |
| Titulo (es subserie) | [540] |
| Titulo (tiene suplemento/inserc.) | [550] |
| Titulo (es suplemento/inserc.) | [560] |
| Titulo Anterior (continuación) | [610] |
| Titulo Anterior (continuación Parcial) | [620] |
| Titulo Anterior (absorbió) | [650] |
| Titulo Anterior (Absorbido/Parte) | [660] |
| Titulo Anterior (subdiv. de) | [670] |
| Titulo Anterior (fusión con) | [680] |
| Titulo Posterior (continuado por) | [710] |
| Titulo Posterior (continuado en parte) | [720] |
| Titulo Posterior (absorbido por) | [750] |
| Titulo Posterior (absorbido en parte) | [760] |
| Titulo Posterior (subdividido) | [770] |
| Titulo Posterior (fusionado con) | [780] |
| Titulo Posterior (para formar) | [790] |
| Notas Generales | [900] |
| Fecha de Creación | [940] |
| Fecha de Modificación | [941] |
| Documentalista (creación) | [950] |
| Documentalista (modificación) | [951] |
| Índice General |
Tópicos
- ¿Qué es iAH?
- ¿Donde se instala iAH?
- ¿Quién Instala iAH?
- Paquete de Instalación
- ruta IAH/BASES/IAH
- ruta IAH/DATA/IAH
- ruta IAH/CGI-BIN
- ruta IAH/CGI-BIN/IAH
- ¿Como Instalar iAH?
- Directorios para las Bases de Datos
- Procedimientos para la instalación del paquete
- Directorios para las Páginas de Acceso a la Interface
- Procedimientos para la instalación del paquete
- Directorio para la Ejecución de Scripts
- Procedimientos para la instalación del paquete
- Edición del archivo IAH.DEF
- Procedimientos para la instalación del paquete
- Prueba inicial del Sistema
- Bases de Datos Propias
- Configuración de Bases de Datos
Tablas
- Tabla-1: Equivalencias de directorios
- Tabla-2: Secciones y funciones del IAH.DEF
- Tabla-3: Comparativo de técnicas de indización
- Tabla-4: Comparativo de técnicas de indización
- Tabla-5: Sección y funciones de base.DEF
- Tabla-6: Elementos de la definición de índices
- Tabla-7: Identificadores de Formularios
Figuras
- Figura-1: Estructura de directorios en el servidor Web
- Figura-2: Organización de directorios del paquete
- Figura-3: Directorios para las Bases de Datos
- Figura-4: Directorios para Páginas Estáticas
- Figura-5: Directorios para Ejecución de la Aplicación
Apéndices
- Apéndice A - Técnicas de Indización
- Apéndice B - Campos LILACS (Metodología BIREME)
- Apéndice C - Campos SeCS Catalogo (metodología BIREME)